자연어처리, 생성형 AI, GPT 및 AI 시스템 개발

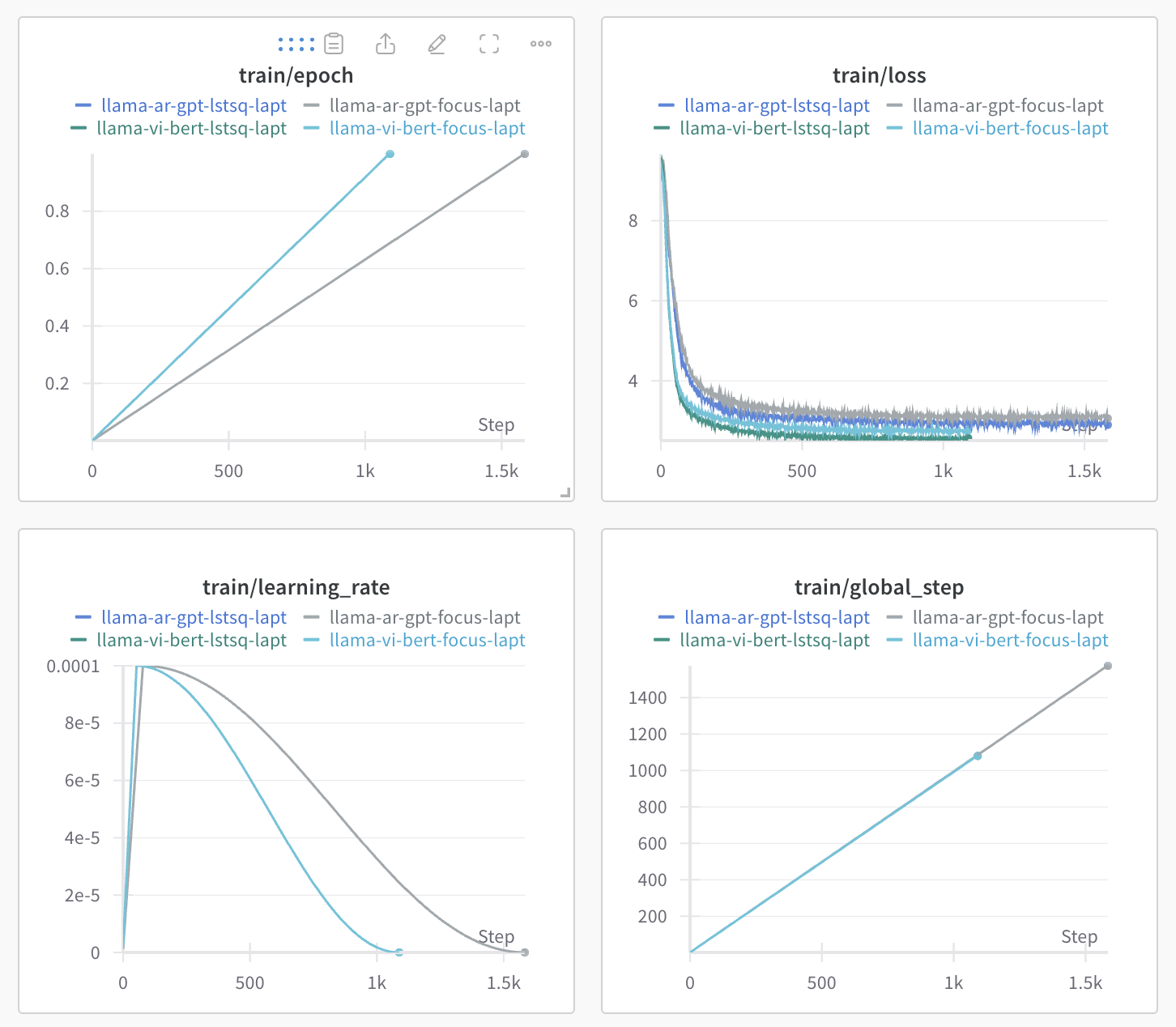
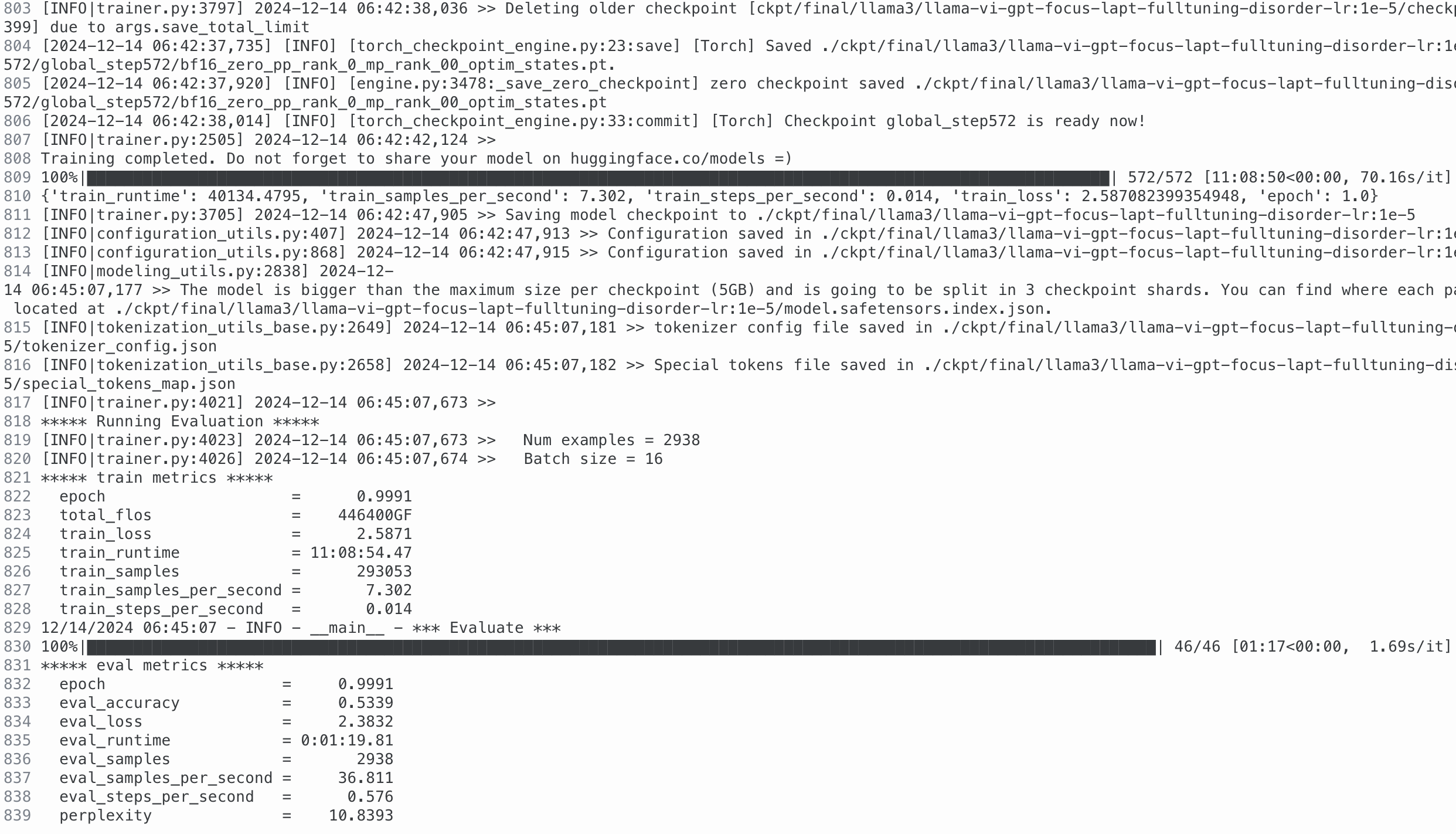
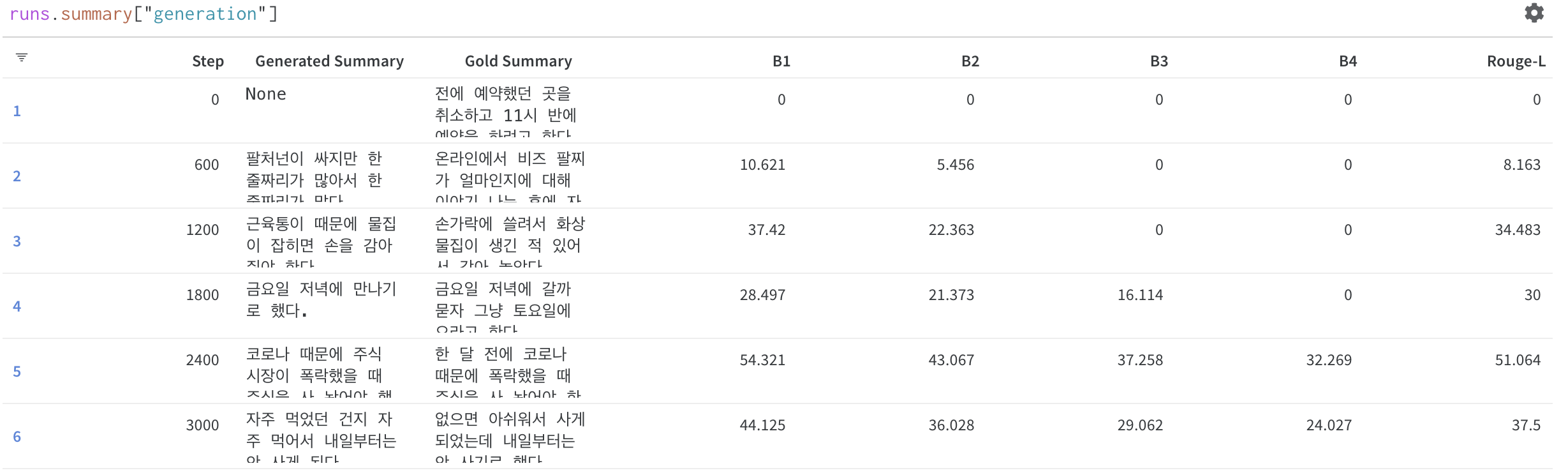
저희는 자연어처리 기술을 기반으로 인공지능 서비스를 개발합니다.특히 저희는 생성형 AI 를 전문으로 하는 전문 인력으로 구성되어있습니다.현재 생성형 AI는 많은 것을 가능하게 하지만, 학습부터 시작하여 모델을 구축하고 배포하는 비용은 상당히 높은 수준입니다. 또한 저희는 개발을 진행하면서, 이러한 기술을 서비스에 연계하시는 방법을 고민하시는 분들을 많이 보았습니다.이에 저희는 의뢰인께서 제시해주시는 과업에 대해 효율적으로 접목할 수 있는 방법을 함께 고민하며, 방향을 제시하고 기술적 구현을 통해 문제를 해결해 드리고자합니다.다양한 경험과 프로젝트들을 통해 습득된 노하우를 접목하여, 합리적인 비용으로 완성도 높은 결과물을 제공해드리도록 하겠습니다.약력구체적인 약력은 다음과 같습니다.- 해외 자연어처리 탑티어 컨퍼런스(ACL, NAACL, EMNLP 등) 논문 다수 보유- 국내 자연어처리 학술대회 논문 다수 보유- 매년 정부 출연 과제 및 기업 과제 수행, 기술이전 보유- Gemma 및 Llama 기반 한국어 LLM 개발- ㄱ대학교 연구인력으로 근무- ㄱ대학교 인공지능 전공 석박사 통합과정 재학- 국내 다국어 번역 시스템 개발 그룹 소속- SKT / ITRC 주관 ICT 챌린지 과학기술부 장관상 수상 2회- 통계청 주관 AI 경진대회 및 데이콘 수상 - N사 및 U사 NLP 3년 연속 교육 협력타겟 서비스저희가 타겟으로 하고있는 서비스는 다음과 같습니다.- 사전학습 모델(PLM: BERT / GPT / BART / T5) 기반 학습 및 평가- Llama, Gemma, Qwen 등의 대규모 언어모델 (LLM) 학습, 평가 및 배포- OpenAI의 ChatGPT, GPT-3.5, GPT-4 등의 API 활용 서비스- 목적 지향 대화 시스템 (TOD) 개발- RAG를 위한 임베딩, 모델 및 파이프라인 개발- 도메인 특화 / 다국어 특화 언어모델 개발- 이외 최신 자연어처리 기술을 활용한 프로젝트- NLU(자연어 이해작업): 분류, 형태소 분석, 개체명 인식 등- NLG(자연어 생성작업): 문서 요약, 질의 응답, 번역 등- 규칙 기반 및 통계기반 NLP활용 서버 스펙저희 팀은 여러대의 고성능 GPU(A6000, A100) 서버 노드들을 통해 PLM의 경우 모든 형태의 학습이 가능하며, LLM의 경우 최대 7B 규모까지의 Continual, Further Pre-training 및 Fine-tuning을 지원해드리고 있습니다. 의뢰자분의 요구에 맞추어 파이프라인을 구성하여 학습 및 평가를 진행합니다. 해당 과정에서 산정되는 작업 규모와 소요 시간 및 서버 비용에 따라 요금이 변동될 수 있습니다.저희는 신뢰성 있고 지속가능한 형태의 서비스 개발을 지향합니다. AI는 이에 더 빠르게 다가서는 훌륭한 도구로 활용될 수 있다고 확신합니다. 이러한 서비스로의 도약을 저희는 여러분과 함께하고 싶습니다. 언제든지 편하게 상담주시면, 정성껏 응대해드리도록 하겠습니다. 저희의 서비스 제공절차 4단계로 이루어집니다.1. 작업 세부사항 및 프로젝트 규모 협의- 의뢰자분께서 요청주신 작업에 따라 전반적인 파이프라인을 수립하고, 프로젝트 규모를 산정합니다. 이에 따라 최종 작업 기한 및 비용을 협의에 따라 결정합니다.2. 프로젝트 진행- 요청이 완료되면 협의된 파이프라인에 따라 프로젝트를 진행합니다.3. 프로젝트 진행사항 공유- 의뢰인 분의 요청에 따라 작업 진행사항을 공유해드립니다. 4. 최종 산출물 전달- 작업이 완료되면 설명, 모델, 코드, 실행 로그 등의 최종 결과물을 전달드립니다. 요청하고자하시는 작업의 목적과 대략적인 결과물을 전달해주시면 가장 좋습니다.또한 활용 가능한 데이터가 있으시다면 샘플을 전달해주시면 감사하겠습니다.일반적으로는 채팅으로 운영하고있으며, 규모가 큰 작업의 경우 별도 협의하여 비대면 미팅이 가능합니다.